На конференції Web 2.0 у 2006 році Марісса Майєр з Google вказала на проблему, що додаткові пів секунди затримки призводили до зниження пошукового трафіку приблизно на 20%. Amazon повідомляв про подібний ефект: кожні додаткові 100 мс зменшували продажі приблизно на 1%.
Великі затримки часу відгуку частіше можна зустріти в аналітичних SQL-запитах, оскільки запит вимагає обробки великих блоків даних. Особливо сильно затримки впливають на клієнтів з тривалою історією покупок. Саме вони найчастіше опиняються в верхніх перцентилях часу відгуку — а це ті самі користувачі, яких компанії найменше хочуть втратити.
Конференція відбулася майже 20 років тому, комп'ютерні технології за цей час стали демократичнішими, що призвело до збільшення кількості користувачів і продуктів. Проблема затримок не зникла — навпаки, вона стала гострішою: чим більше інформації накопичують сервіси, тим важче стає її обробка. Щоб впоратися з навантаженням, доводилося змінювати архітектурні підходи до зберігання та обробки даних. У статті ми розберемо один з них – event-driven design.
Що це за підхід і навіщо він потрібен?
Зі зростанням бізнесу навантаження на дані стає критичним. Для онлайн-маркетплейсу це можуть бути персоналізовані рекомендації, для фінтех-проекту — антифрод, що відстежує підозрілі транзакції. В обох випадках дані потрібно обробляти постійно, наближаючись до обробки в реальному часі.
Але частий запуск аналітичних SQL-запитів швидко перевантажує базу: доводиться фільтрувати, вибирати та розподіляти рядки з величезних блоків інформації. Спроба «зберегти статистику заздалегідь» теж не вирішує завдання, тому що аналітика динамічна — найменша зміна умов здатна повністю змінити стратегію сервісу. Тому довгий час стандартною практикою було виконання запиту прямо при вході користувача, з частковим кешуванням результатів. Така «лінива» модель перерахунку (lazy calculation) погано масштабується.
Альтернативою став event-driven design. Замість того щоб чекати запит користувача та перераховувати дані з нуля, система реагує на самі події — покупку, транзакцію, клік. Інформація оновлюється в момент її появи, і сервіс завжди готовий видати свіжі результати без затримки.
Спочатку розберемо, як еволюціонували підходи до взаємодії з базою даних. Розберемо недоліки існуючих засобів покращення продуктивності.
Частина I. Оптимізація в OLTP базі даних
Чи можна якось оптимізувати тільки за допомогою бази даних?
У випадку найпростішої обробки статистики, ланцюжок сервісів зберігає кожну подію, що бере участь в аналізі, здійснену користувачем або фоновим процесом, в базу даних. При необхідності отримати результат, виконується SQL запит з групуванням та агрегацією значень. База даних виконує пошук у знімку даних для нівелювання впливу паралельно виконуваних транзакцій на цілісність вибірки
З конкурентністю також пов'язана суттєва частина затримок через необхідність синхронізації. При масових аналітичних запитах ситуація погіршується: навантаження на механізми блокувань та контроль ізоляції транзакцій зростає. В результаті база даних витрачає більше часу на координацію паралельних операцій, виконує повторні сканування рядків та додаткову фільтрацію.
Першим кроком до покращення швидкості запиту є планування архітектури самих таблиць. Дані таблиці повинні бути нормалізовані та спроектовані таким чином, щоб мінімізувати дублювання даних, спростити оновлення, процедуру об'єднання та забезпечити логічну цілісність, зберігаючи баланс між ступенем нормалізації та продуктивністю запиту
Наступний пункт - індекси, що являють собою допоміжні структури даних, створені для прискорення пошуку. Індекси є вторинними відсортованими таблицями, що містять посилання на відповідні рядки основної таблиці. Завдяки структурі індексу, СУБД може виконувати фільтрацію та вибірку даних швидше, не скануючи всю таблицю повністю
Індекси не використовуються автоматично. Наприклад, їх застосовність залежить від селективності — відношення кількості унікальних значень у стовпці до загальної кількості записів. Чим ближче селективність до одиниці, тим вища ймовірність, що індекс буде використаний. Наприклад, індекс за полем "ID" з унікальними значеннями майже завжди корисний, тоді як за булевим полем — ні.
Крім того, кожен оператор модифікації в таблиці з індексами вимагає їх оновлення, що веде до додаткового навантаження. Тому, незважаючи на очевидну користь у низці випадків, індекси не є універсальним рішенням і повинні використовуватися тільки при явній економії ресурсів у більшості запитів
Чи можна покращити продуктивність переписавши запит, використовуючи альтернативні конструкції?
Для цього методу немає якихось універсальних порад, кожен запит повинен розглядатися індивідуально, виходячи з особливостей вашої СУБД. Існують загальні методи оптимізації, як допоміжна фільтрація, денормалізація даних або створення тимчасової таблиці для кешування результатів. Написання ефективних запитів - навичка, що вимагає високого досвіду розробника; Перехід на іншу СУБД може звести нанівець переваги вже оптимізованих запитів, а складність написаної реалізації може перетворити високонавантажений ділянку коду в ящик Пандори будь-якого релізу, тому, якщо це можливо, хорошою практикою є зміщення відповідальності за покращення перформансу з розробника на інше програмне рішення, заточене під вирішення даної задачі
А що щодо внутрішнього кешування?
Сучасні реляційні СУБД використовують вбудовані механізми прискорення — наприклад, буферний кеш сторінок та план-кеш для часто виконуваних запитів. Це дійсно може покращити час відгуку, але покладатися тільки на внутрішні алгоритми бази не варто: при зростанні навантаження RPS рано чи пізно просяде
Частина II. Аналітичні бази даних
Аналітичні запити можна виконувати й в окремій базі даних. Оновлення даних та аналітичні запити — навантаження різного характеру, які призводять до взаємних блокувань або просто витрачають величезну кількість ресурсів. Рішень може бути кілька: перехід на Read/Write репліки або використання OLAP сховищ. Зупинимося на останньому докладніше
Що таке OLAP сховище і коли воно краще?
OLTP база даних оптимізована як для запису, так і для читання, тому найчастіше використовується в production середовищі як основний інструмент управління даними. OLAP сховище виграє при частому читанні, фільтрації, агрегації, але має суттєвий недолік у швидкості оновлень та вставки даних. Характер зберігання даних може бути різним: нескладні Data Lake сховища, де дані зберігаються в неструктурованому вигляді, а обробка даних відбувається під час читання даних, так і різні системи зберігання даних у вигляді багатовимірних кубів, де залежно від запиту будуть використані конкретні площини, кількість яких у сучасних реалізаціях технічно може перевищувати сотню.
Сучасні бази даних реального часу, такі як ClickHouse, Apache Druid, StarRocks пропонують функціонал та інструменти попередньої обробки записів за допомогою тригерів. Дані, надходячи в одне з вищезгаданих сховищ, можуть оброблятися матеріалізованими поданнями та застосовувати вже закешованим результатам. У цьому випадку при запиті користувача, БД видасть підготовлені дані, приводячи час затримки до мінімуму
Але як згадувалося вище, будь-які операції модифікації досить складні в OLAP сховищах, більшість аналітичних движків спочатку проектувалися під модель, де дані простіше додавати, ніж модифікувати. Це сильно впливає на характер використання подібних систем та накладає архітектурні обмеження
Класичний спосіб управління даними для архітектури REST - CRUD передбачає часті додавання, оновлення, видалення. У випадку реплікації даних з OLTP бази в OLAP без зміни структури зберігання записів, ми отримаємо повільні операції модифікації та, як наслідок, збільшення інтервалу кінцевої узгодженості двох баз даних
Частина III. Журнал подій
Статистичні запити часто не мають явних часових меж, що призводить до повного сканування записів у таблиці. А в випадку з плановими, наприклад квартальними, запитами модель подання даних не гарантує, що дані не могли застаріти через нове оновлення вже існуючих записів.
Як наслідок при надходженні нових даних у довгостроковій перспективі:
- Час виконання цих запитів буде статично зростати
- Велика частина даних буде оброблена більше одного разу
Ситуацію змінює перехід на іншу стратегію зберігання даних – журнал подій. Структура гарантує, що записи не будуть оновлені або видалені, а будь-яка зміна породжує новий запис у базу даних, що компенсує якесь діяння
Розберемося на практичному прикладі з балансами користувачів, проектуючи подання за допомогою принципів append-only журналу:
Замість того, щоб зберігати в таблиці користувачів значення балансу, ми будемо визначати його на основі операцій з цим балансом. А дані будуть представляти собою тільки зміну даних, а не їх кінцеве стан.
На лівій частині рисунка, в таблиці users містяться унікальні за користувачем значення балансів. Дані в цій таблиці оновлюються командою SQL при будь-якій зміні
На правій частині, таблиця transactions містить тільки події зміни: поповнення та зняття коштів. Сума цих подій є актуальним балансом.
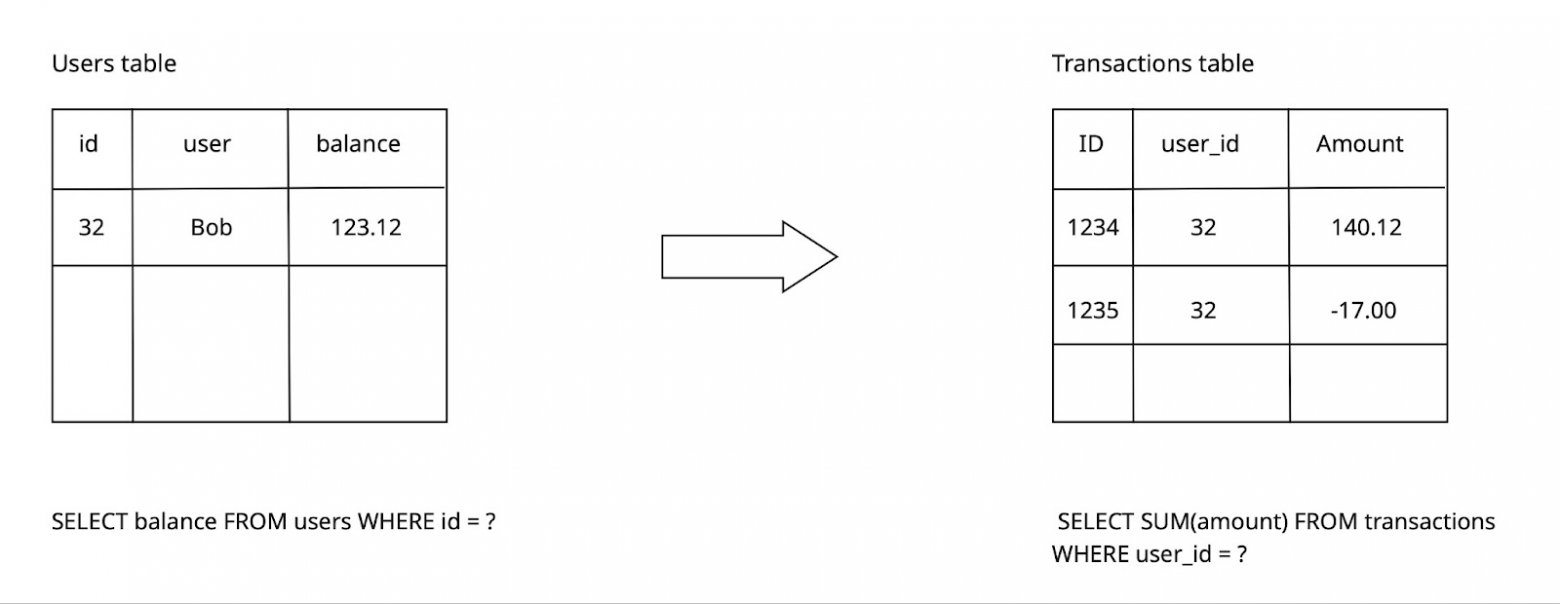 Таблиці для розрахунку балансу
Таблиці для розрахунку балансу
Перевага даної структури зберігання – історичність даних. Записи завжди розташовані в хронологічному порядку. З цього випливає, що взявши будь-яку точку відліку часу, меншу за поточну, ми зможемо отримати актуальне на той момент значення поля. Кожне нове значення випливає з незмінного попереднього
Фіксація змін з мітками часу підрахунку дозволяє зберігати результати агрегації даних та перевикористовувати їх, замість численних перерахунків значень по всіх доступних рядках з БД. Такий метод проектування називається системою знімків даних.
 Часовий ряд подій
Часовий ряд подій
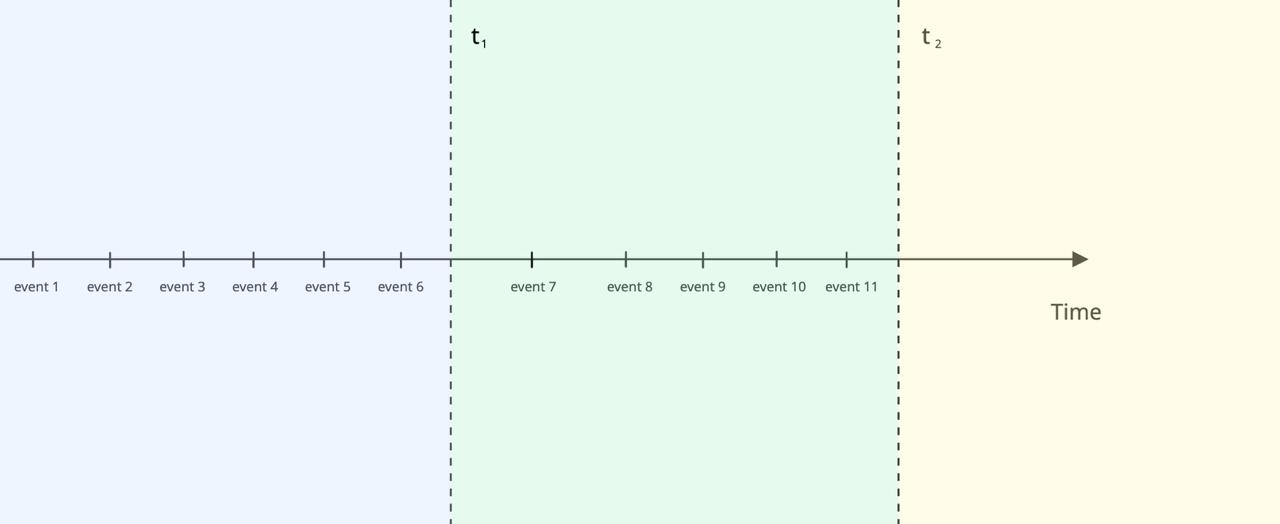
Розберемо на прикладі. Уявимо лінію часу, на якій розташовані події (events) у хронологічному порядку. Позначимо на ній дві контрольні точки — t₁ і t₂.
З початку лінії до моменту t₁ ми обробили події 1–6 та зберегли результат агрегації у допоміжну таблицю. Даний запис є знімком стану.
Коли настає момент t₂, ми обробляємо тільки нові події 7–11. Щоб отримати актуальний стан, нам не потрібно перераховувати всі події з 1 по 11. Достатньо взяти збережений результат у точці t₁ та додати до нього агрегацію нових даних:
final_state = previous_agg + agg(events WHERE created_at > previous_agg.created_at)
Таким чином, ми рухаємо часове вікно та обробляємо тільки «незафіксовані» зміни. Це знижує навантаження: замість постійного перерахунку всієї історії система працює з невеликими частинами даних. Актуальність при цьому гарантується тим, що вже зафіксовані події залишаються незмінними.
Поєднуючи структуру append-only журналу з системою знімків даних, ми вирішуємо проблему постійного перерахунку одних і тих самих даних, а також статичного збільшення часу виконання аналітичних запитів:
- Підраховані агрегації даних будуть зберігатися у якості знімків даних, замість перерахунку старих даних ми будемо використовувати раніше збережені результати
- Розмір розраховуваних даних залишається незмінним або майже незмінним (залежно від політики їх створення: за часовими інтервалами або кількістю подій)
Також такий підхід спрощує механізм реплікації: зміни будуть являти собою новими рядками в таблиці, тому немає необхідності сканувати таблицю при кожному такті реплікації.
Подібна організація зберігання даних лежить в основі сучасних стримінгових платформ. За нашою думкою, найбільш повно її реалізує Apache Kafka, яка виступає розподіленим журналом подій з можливістю реплікації та паралельної обробки групою споживачів з гарантією доставки подій
Частина IV. Kafka Stream і ksqlDB. Потокова обробка подій
Другий продукт від Confluent - Kafka Streams був створений для обробки повідомлень з топіків Kafka, використовуючи операції map, filter, aggregate, join, etc… Результати цих агрегацій потрапляють в іншу топіку у вигляді повідомлення, яке також можна використовувати як джерело для нового оператора. Така модель дозволяє організовувати пайплайни подій, через що KStreams активно використовується як дистриб'ютер агрегованих повідомлень між мікросервісами
Обробка даних ведеться за допомогою споживання повідомлень та групування за допомогою коду бібліотеки. Офіційна версія продукту доступна тільки на Java, що суттєво ускладнює використання пакету в проектах, що використовують інший основний мову. Технологія має високий поріг входу, вивчення внутрішніх методів сповільнює розробку, а складні операції організації даних реалізуються пліч-о-пліч з бізнес-логікою сервісу. Kafka Streams була першою версією нового підходу до обробки подій, що отримала визнання та інтерес з боку спільноти розробників.
У 2017 році Confluent представила нове рішення — Kafka SQL (ksqlDB), яке усунуло низку недоліків попередніх підходів. Тепер запити до даних виконуються не в користувацькому коді, а через розгорнутий сервіс ksql-server (наприклад, в Docker), використовуючи HTTP-запити. Для опису логіки застосовується SQL, що лише злегка відрізняється за семантикою від класичного. Це знижує поріг входження: достатньо базових знань SQL, щоб швидко почати працювати з потоками даних.
При цьому збереглися знайомі з Kafka Streams структури даних:
Stream (потік) — незмінний конвеєр подій. Користувач задає схему з типізацією, і кожне повідомлення, що потрапило в Kafka-топік, записується в відповідні поля потоку. Якщо поле відсутнє в події, Kafka трактує його як zero-value. В Kafka SQL немає оновлення або видалення подій: кожне нове повідомлення — це окремий event, а модифікація або видалення виражаються через компенсуючі події.
Table (таблиця) — близька за суттю до потоку, але зберігає не всю послідовність подій, а тільки актуальне значення за ключем. Групування задається користувачем при створенні таблиці, за допомогою конструкції PRIMARY KEY.
Завдяки типізованій структурі, кожне поле події зберігається в свою колонку. З цього моменту ми можемо використовувати широкий інструментарій запитів ksql:
Вибірка, Фільтрація, об'єднання, агрегація, створення вікон та арифметику над числовими значеннями
Більш детальний опис можна прочитати в офіційній документації
Частина V. KSQL на практиці
Чотири місяці тому ми вперше спробували запитати статистику за допомогою KSQL та були здивовані зручністю технології. На той момент не існувало жодної бібліотеки на нашій основній мові Golang, тому спочатку ми використовували CURL запити, а пізніше й зовсім вирішили написати свій пакет взаємодії з сервісом. По мірі розробки ми додали звичні нам фічі, за якими скучали перейшовши на нову технологію: query builder, query reflection, CLI migrations. У подальших прикладах ми будемо використовувати як стандартні запити, так і код нашої бібліотеки, для реалізації складних прикладів взаємодії з KSQL
Розберемо на прикладі
Уявимо, що ми займаємося сервісом нарахувань бонусної програми користувачів. У якості потоку подій буде топік Kafka з назвою purchases. Опишемо структуру подій:
Ідентифікатори, такі як CustomerID, ProductID тощо, посилаються на записи в таблицях ksqlDB. Таблиці найкраще підходять в цій ситуації, т.к. вони будуть зберігати лише останнє актуальне стан та надсилати подію тільки при зміні.
Потік подій з покупками буде початком конвеєра,
Для подальшої роботи, заведемо потік bonus_invoices, який буде реєструвати події зміни бонусного балансу користувача. Для кожної покупки створимо «нарахування бонусів» як 10% від суми (quantity × price):
Події об зміні балансу користувачів потрібно кудись записувати, заведемо таблицю bonus_balances, яка буде агрегувати потік змін:
Варто згадати про push/pull queries. ksqlDB надає можливість виконання одноразового запиту (pull queries), який поверне значення один раз і завершить своє виконання. Другий варіант – push query буде являти собою повисле TCP-з'єднання, а результати обробки будуть повертатися при кожній зміні. Тут ми це вказали, використавши спеціальне слово EMIT CHANGES. Нам потрібно рахувати баланс по всіх змінах балансу, і майбутніх теж, а не вираховувати його один раз.
Таблиця бонусних балансів у нас реалізована. Тепер реалізуємо підрахунок рівнів лояльності користувачів. Нехай буде 3 рівні:
- бронзовий (бонусний баланс менше 10_000)
- срібний (бонусний баланс більше 10_000 і менше 50_000)
- золотий (бонусний баланс більше 100_000)
Ці три рівні розраховуються протягом року, тому нам потрібно реалізувати механізм віконного підрахунку балансів. Це можна реалізувати за допомогою умовних операторів та спеціального методу WINDOW:
Таким чином ми побудували конвеєр роботи з бонусною програмою. Важливо, що при подальшій розробці цей граф обчислень може досить просто розширюватися. У нас є повноцінний пакет ksql-examples, де ви можете подивитися на більш розгорнуті графи обчислень.
Розробка бібліотеки ведеться і зараз, на поточний момент вона знаходиться в ранній бета-версії. Дошка з issues заповнена задачами з покращення проекту та зібрана по планах на подальші релізи. Пакет відкритий для всіх бажаючих розробляти open-source продукт або ж до об'єктивного погляду з боку. Ми були б раді будь-якому обговоренню в коментарях.
Джерела:
- https://glinden.blogspot.com/2006/11/marissa-mayer-at-web-20.html
- https://clickhouse.com/docs/best-practices/use-materialized-views
Коментарі