У сучасних мікросервісних архітектурах кешування відіграє ключову роль у забезпеченні високої продуктивності, масштабованісті та стійкості систем. Правильне застосування патернів кешування дозволяє значно знизити навантаження на бази даних, зменшити час відгуку та підвищити загальну пропускну здатність системи.
Що являють собою патерни кешування?
Розгляньмо п’ять основних патернів кешування, які застосовуються в розробці.
Cache‑Aside — це найінтуїтивніший і часто використовуваний патерн. Його можна зустріти під назвою патерн ледачого завантаження. Додаток виступає в ролі «контролера», самостійно керуючи процесом кешування. Коли потрібно отримати дані, додаток спочатку звертається до кешу. Якщо дані знайдені — вони повертаються негайно. У протилежному випадку запускається запит до основного сховища, отримані дані зберігаються в кеш, а потім повертаються користувачеві. Цей підхід особливо ефективний, коли не всі дані в системі потребують кешування — кеш заповнюється лише за необхідності. Однак він не захищає від ситуацій, коли одночасно багато користувачів запитують одні й ті самі дані, яких ще немає в кеші — це призводить до ефекту «thundering herd».
Read‑Through Cache пропонує більш абстрактний підхід до роботи з даними. На відміну від Cache‑Aside, додаток взаємодіє виключно з кешем, який сам відповідає за завантаження даних із джерела за їх відсутності. Це спрощує логіку додатка, оскільки він більше не турбується про те, чи є дані в кеші чи ні. Такий патерн особливо корисний у системах, де важливо забезпечити єдиний інтерфейс доступу до даних. Однак він вимагає ретельнішого налаштування політик витіснення і може бути менш гнучким у сценаріях, де частина даних не потребує кешування.
Write‑Through Cache гарантує узгодженість даних між кешем і основним сховищем. При кожній операції запису дані одночасно зберігаються і в кеші, і в базі даних. Це забезпечує те, що при наступному читанні дані будуть доступні негайно з кешу. Такий підхід ідеально підходить для систем, де актуальність даних є критичною. Однак він може стати вузьким місцем при високому навантаженні на запис, оскільки кожна операція вимагає оновлення двох систем. Крім того, дані, які рідко запитуються, все одно займатимуть місце в кеші.
Write‑Around Cache пропонує протилежний підхід — дані записуються лише в основне сховище, минаючи кеш. Це запобігає «забрудненню» кешу даними, які можуть ніколи не знадобитися для читання. Такий патерн економить пам’ять кешу для дійсно затребуваних даних. Цей підхід особливо ефективний у сценаріях, де запис відбувається часто, а читання — рідко. Однак він може призвести до збільшеного часу відгуку при першому читанні записаних даних, оскільки вони повинні бути завантажені з основного сховища і поміщені в кеш.
Write‑Back Cache забезпечує максимальну продуктивність при операціях запису. Дані спочатку записуються в кеш, а потім асинхронно передаються в основне сховище. Це дозволяє значно прискорити операції запису і навіть групувати кілька операцій для оптимізації. Такий патерн ідеально підходить для write‑heavy систем, де важлива висока пропускна здатність. Однак він несе ризик втрати даних у разі збою кешу до того, як дані будуть синхронізовані з основним сховищем. Крім того, підтримка узгодженості даних у розподілених системах стає значно складнішою.
Кожен з цих патернів має свої сценарії застосування. Cache‑Aside підходить для більшості випадків, Read‑Through спрощує архітектуру, Write‑Through гарантує узгодженість, Write‑Around економить ресурси кешу, а Write‑Back забезпечує максимальну продуктивність.
При виборі патерна необхідно враховувати характер навантаження, а також вимоги до узгодженості даних і допустимий рівень складності реалізації.
Приклад реалізації Cache-Aside
З врахуванням того, що патерн кешування Cache‑Aside є найбільш універсальним, ми розглянемо його реалізацію докладніше.
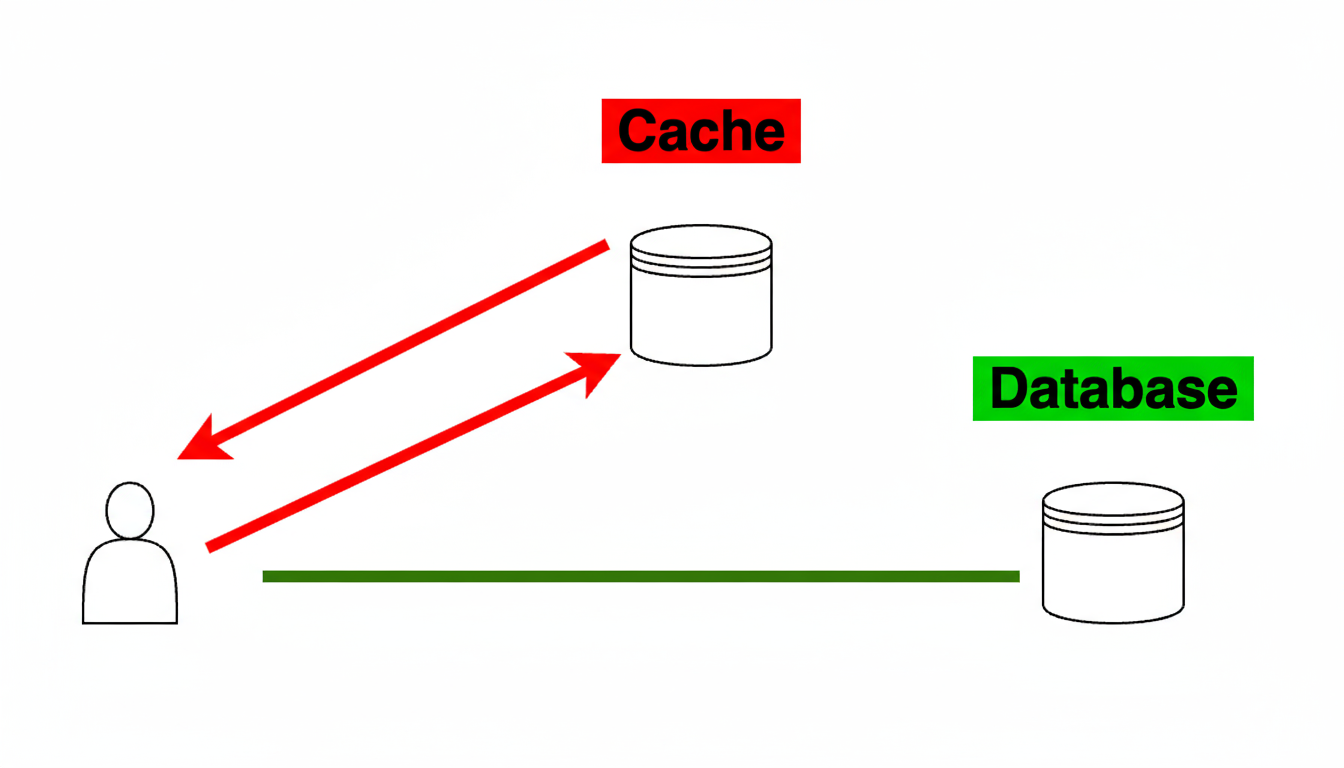
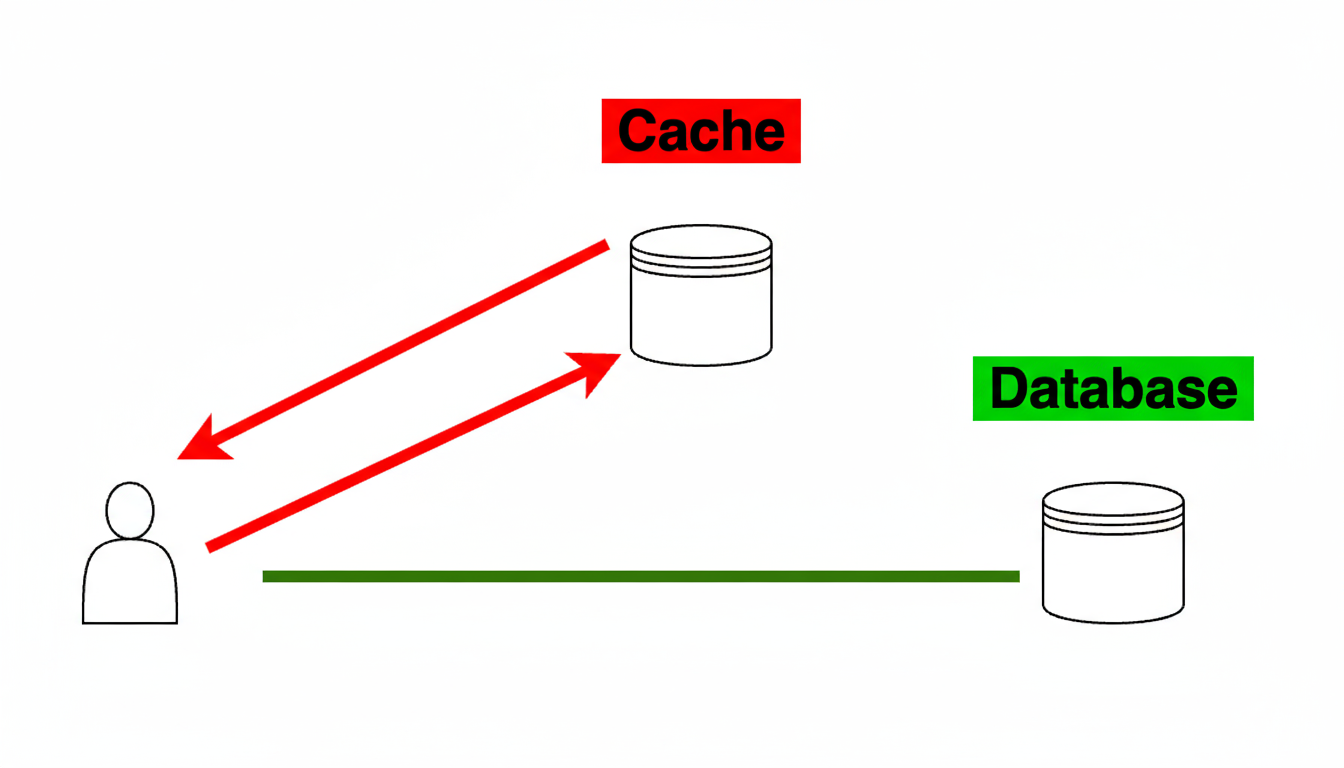
На малюнку 1 зображена схема роботи патерну Cache‑Aside. Додаток спочатку перевіряє кеш. Якщо дані знайдені в кеші, це називається попадання в кеш (cache hit), і дані відразу зчитуються і повертаються клієнту.
Однак, якщо дані відсутні в кеші, відбувається промах кешу (cache miss), і тоді додатку доводиться виконати додаткову роботу: запитати дані з бази даних, повернути їх клієнту і зберегти в кеші для забезпечення попадання в кеш при наступних зверненнях до цих саме даних.
Розгляньмо тепер його найпростішу реалізацію для розуміння того, як все працює. І в цьому нам допоможе Java і Spring Framework.
Для початку підключимо залежності в build.gradle:
І опишемо нашу модель даних, яку будемо використовувати в запитах нашого додатка:
І реалізуємо сервіс, який буде імітувати базу даних і виконувати всю логіку патерна Cache‑Aside.
Для імітації бази даних будемо використовувати клас ConcurrentHashMap, в який через анотацію @PostConstruct додамо набір сутностей:
Для реалізації кешу будемо використовувати той же клас ConcurrentHashMap, який буде потокобезпечним і буде зберігати кешовані дані:
Тепер розглянемо реалізацію getUserById(Long id) на основі патерна Cache‑Aside. Для цього реалізуємо логіку з трьох кроків:
КРОК 1: Перевіряємо кеш і повертаємо користувача якщо він там є:
КРОК 2: Кеш-промах - якщо користувача не знайшли в кеші, то завантажуємо його з бази даних:
КРОК 3: Зберігаємо знайденого користувача з бази даних в кеш для майбутніх запитів:
І залишилося додати найпростіший REST‑контролер для можливості формування викликів:
Правильний вибір і реалізація патернів кешування в мікросервісній архітектурі дозволяє досягти значного покращення продуктивності та масштабованісті системи. Кожен патерн має свої сценарії застосування, і вибір залежить від конкретних вимог до системи, характеру навантаження та вимог до узгодженості даних.
Кешування — це лише один з інструментів, що дозволяють підвищити продуктивність і масштабованість мікросервісної архітектури. Але щоб впевнено застосовувати подібні підходи, важливо системно розбиратися в пристрої сучасних серверних додатків і розуміти архітектурні патерни.
Коментарі