← Попередня глава |
У чому секрет успіху трансформерів?
За останні роки трансформери стали найуспішнішою архітектурою нейронних мереж, зокрема в задачах обробки природної мови. Тепер вони наближаються до SOTA й для задач комп’ютерного зору. Успіх трансформерів зумовлений кількома ключовими факторами: механізм уваги, можливість легкої паралелізації, навчання без учителя та велика кількість параметрів.
Механізм уваги
Механізм self-attention, що використовується у трансформерах, є одним із ключових компонентів архітектури, які зробили LLM на основі трансформерів настільки успішними. Проте трансформери далеко неPer перша архітектура, в якій використовуються механізми уваги.
Механізми уваги вперше були розроблені у контексті розпізнавання зображень ще у 2010-му, до того як їх адаптували для допомоги машинному перекладу довгих послідовностей у рекурентних нейронних мережах.
Згаданий механізм уваги був натхненний людським зором, що фокусується на конкретних частинах зображення (фовеальне зір) у будь-який момент, що дозволяє обробляти інформацію в ієрархічному та послідовному порядку. З іншого боку, базовий механізм, закладений у трансформерах — механізм self-attention. Він призначений для задач sequence-to-sequence, таких як машинний переклад або генерація тексту. Він дозволяє кожному токену у послідовності взаємодіяти з усіма іншими токенами, забезпечуючи контекст для представлень кожного окремого токену.
Яка ж унікальність та корисність механізмів уваги? Наприклад розглянемо енкодер, який може опрацьовувати представлення вхідної послідовності або зображень фіксованої довжини. Він може реалізуватися у вигляді повнозв’язаної мережі, згорткової мережі або мережі, основаної на механізмі уваги.
У трансформерах енкодер використовує механізм self-attention для обчислення важливості кожного токена у послідовності стосовно інших токенів послідовності, дозволяючи моделі фокусуватися на найбільш релевантних частинах вхідної послідовності. З першого погляду робота механізмів уваги нагадує процеси, що відбуваються у повнозв’язаних нейронних мережах, де кожен вхідний елемент пов’язаний з вхідним елементом наступного шару з визначеною вагою. Однак у механізмах уваги ваги обчислюються шляхом порівняння кожного вхідного елемента з усіма іншими. Внаслідок цього ваги уваги стають динамічними і залежать від самих вхідних даних. У повнозв’язаних та згорткових мережах, навпаки, ваги залишаються фіксованими після навчання, як показано на Рисунку 1.1.
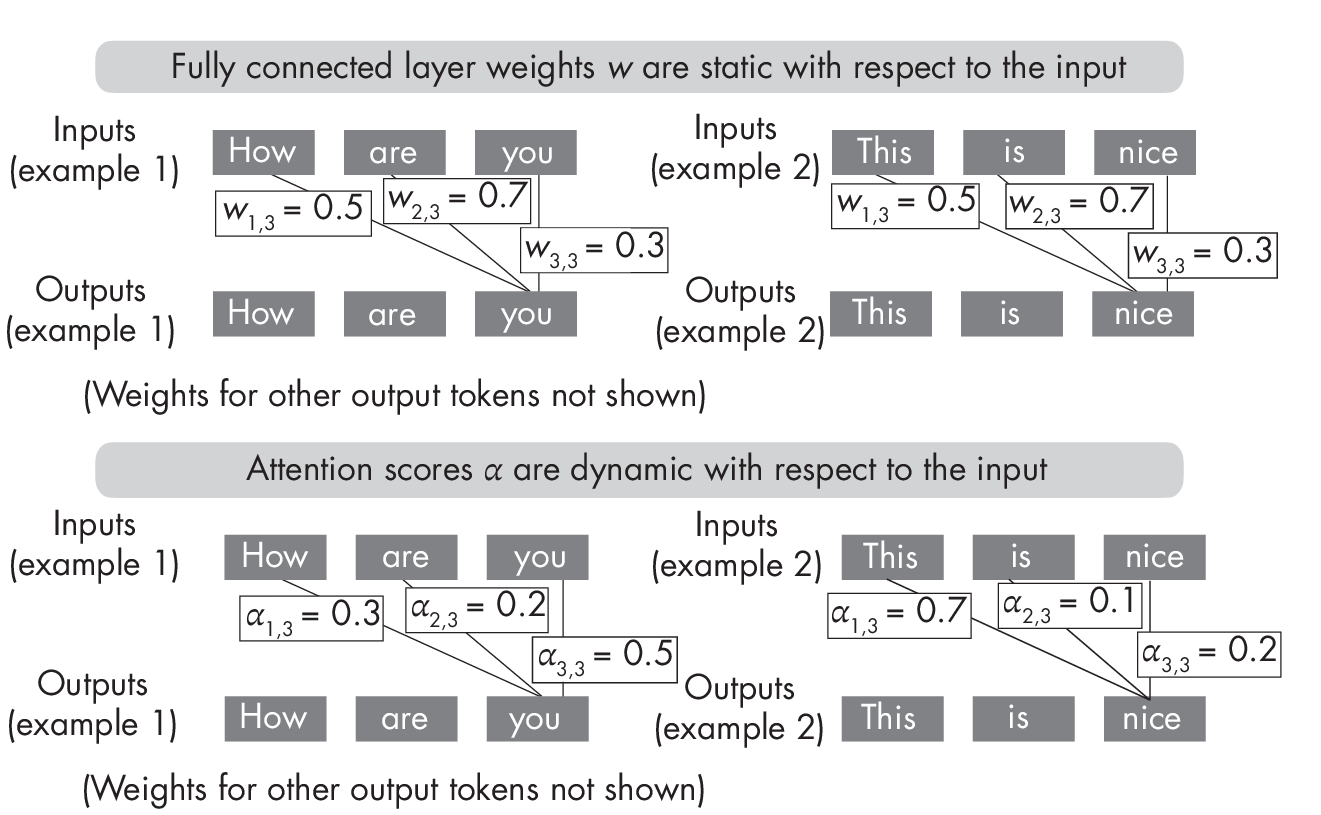 Рисунок 1.1: Концептуальна різниця між вагами моделі у повнозв’язаних шарах (зверху) та вагами уваги (унизу)
Рисунок 1.1: Концептуальна різниця між вагами моделі у повнозв’язаних шарах (зверху) та вагами уваги (унизу)
Як показано на верхній частині Рисунка 1.1, після завершення процесу навчання ваги у повнозв’язаному шарі залишаються незмінними, незалежно від вхідних даних. З іншого боку, як показано знизу, ваги уваги механізму self-attention змінюються залежно від вхідних даних навіть після завершення навчання трансформера.
Механізми уваги дозволяють нейронній мережі не випадково оцінювати важливість різних вхідних даних, так що модель може зосередитися на найбільш важливих для конкретного завдання частинах. Таким чином, у моделі з’являється контекстне розуміння кожного слова або токена зображення, що дозволяє створювати більш точні інтерпретації вхідних даних, що пояснює високу ефективність трансформерів.
Попереднє навчання через Self-Supervised Learning
Успіх трансформерів також зумовлений попереднім навчанням, яке здійснюється за допомогою self-supervised навчання на великих не розмічених наборах даних. У процесі попереднього навчання трансформери навчаються прогнозувати пропущені слова у послідовності або, наприклад, наступне речення в документі. Щоб успішно справлятися з цією задачею, моделі вчаться загальним уявленням про мову, які потім можуть бути використані для дообучення в різних цільових задачах.
Пока попереднє навчання без учителя вже показало високу ефективність для обробки природної мови, його потенціал для задач комп’ютерного зору залишається активною областю досліджень.
Велика кількість параметрів
Варто відзначити, що однією з особливостей трансформерів є великий розмір моделей. Наприклад, популярна у 2020 році модель GPT-3 містить 175 мільярдів навчальних параметрів, тоді як інші трансформери, такі як трансформери з переключенням, містять трильйони параметрів.
Розмір та кількість навчальних параметрів у трансформерах — ключові фактори, які визначають якість моделі, особливо для великих задач обробки природної мови. Згідно з законом лінійного масштабування, функція втрат зменшується пропорційно збільшенню розміру моделі. Це означає, що збільшення розміру моделі у 2 рази може призвести до відповідного зменшення функції втрат.
Це, у свою чергу, може призвести до покращення якості моделі на цільових задачах. Однак дуже важливо, щоб розмір моделі та кількість навчальних токенів масштабувалися пропорційно. Це означає, що кількість навчальних токенів має збільшуватися у два рази при збільшенні розміру моделі вдвічі.
Оскільки кількість розмічених даних обмежена, використання великої кількості даних під час попереднього навчання без учителя є необхідним.
У підсумку, можна сказати, що успіх трансформерів значною мірою зумовлений їх великими розмірами та значними наборами даних. Завдяки використанню self-supervised алгоритмів, здатність трансформерів до попереднього навчання тісно пов’язана з їх значними габаритами та великими наборами даних. Це поєднання факторів стало ключовим для досягнення вражаючих результатів у різних задачах обробки природної мови.
Простота паралелізації
Навчання великих моделей на великих наборах даних потребує величезних обчислювальних ресурсів. Проте, щоб повною мірою використати ці ресурси, обчислення можуть бути розподілені між кількома процесорами.
На щастя, трансформери дуже добре піддаються паралелізації, оскільки вони працюють з послідовностями слів або токенів зображення фіксованої довжини. Зокрема, механізм self-attention, який використовується в архітектурі більшості трансформерів, включає в себе обчислення зваженої суми між парами вхідних елементів. Ці парні обчислення можуть бути виконані незалежно один від одного, як показано на Рисунку 1.2. Завдяки цьому механізм self-attention можна легко розподілити між різними ядрами GPU, що значно підвищує продуктивність моделі.
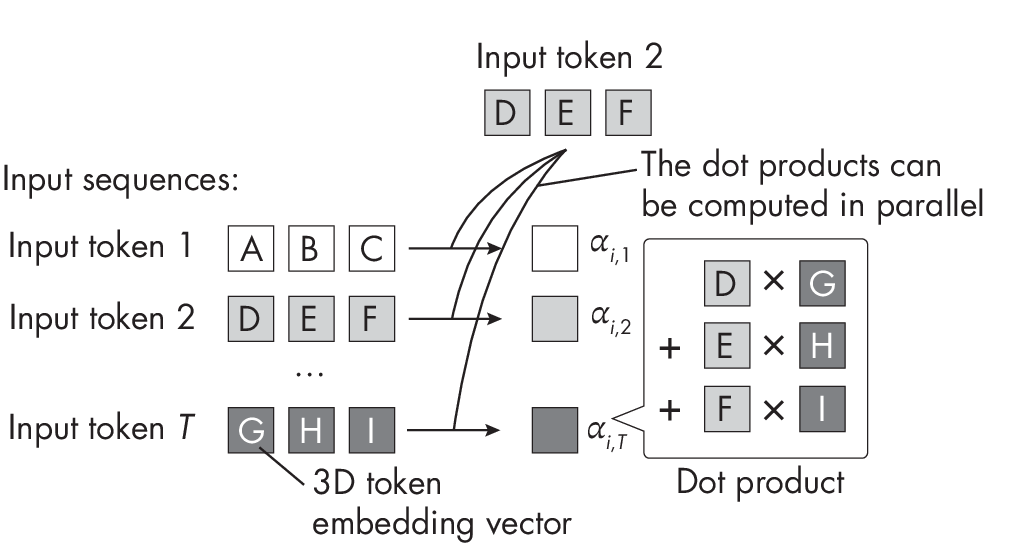 Рисунок 1.2. Спрощений механізм self-attention без вагових параметрів
Рисунок 1.2. Спрощений механізм self-attention без вагових параметрів
Крім того, окремі вагові матриці, які використовуються у механізмі self-attention (не показані на Рисунку 1.2) можуть бути розподілені між кількома пристроями для організації розподілених та паралельних обчислень.
← Попередня глава |
Коментарі