
Сьогодні я розповім, як через випадкову зустріч з ANTLR я створив RCParsing, бібліотеку на C# для парсингу практично будь-якого виду синтаксису, що підтримує парсинг відступів з коробки. Ми розберемося, як працюють різні алгоритми парсингу і чим відрізняється той, що використовується в мене. Також я додам приклад коду для парсингу спрощеного YAML з використанням моєї бібліотеки.
Трохи передісторії
Одного разу я розробляв свій сайт для мультиплеєрних текстових квестів для гри з друзями, а майстром був DeepSeek. Сайт робив на Blazor, а в бекенді було дуже багато інтерполяцій рядків для промптів. Мене ці інтерполяції так розлютили, що в підсумку народилася ідея шаблонної мови спеціально для LLM, подібного до Razor:
У вас могло виникнути питання: "Гей, у тебе ж в синтаксисі дужки, навіщо тобі взагалі відступи знадобилися?", а я відповім: "Для ще однієї мови і просто для особистого інтересу", але про це пізніше.
Відмінності в існуючих підходах до парсингу
З усіх інструментів для парсингу я знав лише ANTLR, тому в першу чергу вирішив спробувати його. Але після усвідомлення принципу його роботи я твердо зрозумів: ANTLR не зможе обробити такий вид синтаксису.
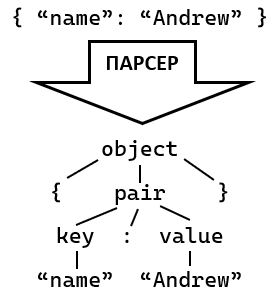
То чому ж? А тому, що він використовує лексер, тобто спочатку розбиває текст на токени (числа, ідентифікатори, рядки, ключові слова тощо), а потім сам парсер працює безпосередньо з ними. Це найшвидший спосіб парсингу (у нього практично завжди стабільна лінійна швидкість, O(n)), хоч і достатньо незручний і негнучкий. Ось наочний приклад, як працює такий парсер:
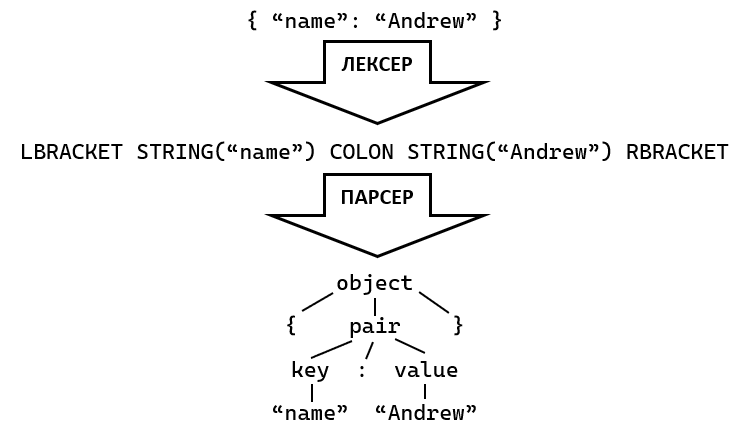 Загальна схема роботи лексерного парсера
Загальна схема роботи лексерного парсера
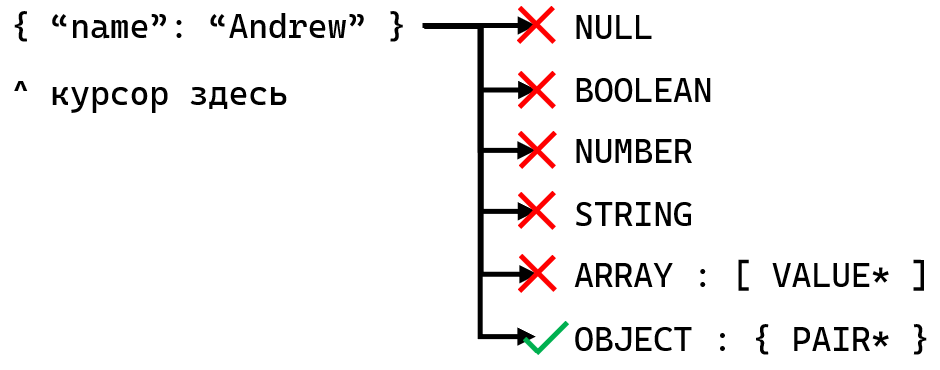
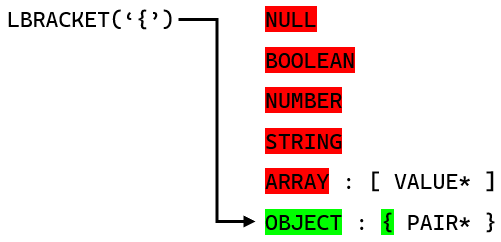 Як лексерний парсер точно обирає правила на основі токенів
Як лексерний парсер точно обирає правила на основі токенів
У чому ж полягає незручність і слабкість такого підходу? Суть в тому, що налаштувати лексер — одне з найскладніших випробувань при створенні такого парсера, так як там потрібно розставляти пріоритети токенам, і, не дай боже, налаштовувати їм режими! Хоча в простих мовах розставити токени по місцях не так вже й складно, а режими взагалі не потрібні, наприклад:
А що якщо в мові більше 100 різних типів токенів, існують інтерполяції рядків і інша єресь? Гляньте цей код лексера для C# і жахніться (до речі, інтерполяція рядків там реалізована не повністю). А ще раджу уявити повноцінний лексер для HTML, де всередині є CSS і JavaScript, всередині якого також може бути HTML. Навіть страшно подумати про Razor, де є і HTML, і C# упереміш...
Але як налаштовувати токени, якщо текст і код змішані, як в моїй мові шаблонів? Коротка відповідь: або змінювати синтаксис мови, або величезним кодом з логікою лексера, або ніяк. Наведу приклад, ось шматок коду з шаблону:
У цьому випадку нам потрібно чітко задати лексеру, де він повинен захоплювати код (ідентифікатори, рядки і всякі символи на кшталт :), а де текст (виключаючи символи @, {, }). І це просто неможливо, так як явні токени-термінали для режимів відсутні, наприклад крапка з комою:
Проблема полягає в тому, що лексер — це достатньо швидка, але примітивна штука, і вона взагалі не в курсі, що у тебе відбувається в тексті. У нас закінчився вираз? Не знаю. У нас почався текст? Коли? У нас є крапка з комою, тепер ти розумієш, де закінчується вираз? Так одразу б і сказали!
Оскільки я не хотів створювати потвору зі своєї мови шаблонів і додавати ці крапки з комами, я вирішив швидко накидати свій, безлексерний парсер, який працює з текстом безпосередньо. Ну а що? Архітектуру я вже придумав, а вже існуючі рішення (на кшталт Sprache і Pidgin) здалися мені незручними.
Через тиждень робочий парсер був вже готовий і він виконував свою задачу на ура. Потім місяць пішов на доопрацювання і оптимізації (перша версія була повільнішою, ніж поточна, в 6 разів!). До речі, ось як в загальних рисах працює безлексерний парсер:
 Загальна схема роботи безлексерного парсера
Загальна схема роботи безлексерного парсера
 Як безлексерний парсер намагається парсити правила по черзі
Як безлексерний парсер намагається парсити правила по черзі
Безлексерний парсер працює з текстом безпосередньо, і це додає в рази більше можливостей для парсингу і прибирає біль налаштування лексера (так як його просто немає). Однак, алгоритмічна складність такого виду парсерів може доходити аж до експоненціальної, але це вирішується мемоїзацією, а в реальних системах швидкість парсингу — не завжди проблема. В цьому підході ті ж ключові слова легко можуть інтерпретуватися як ідентифікатори, на відміну від лексерного підходу.
І найголовніше: безлексерний парсер може захоплювати рівно стільки тексту, скільки потрібно, без зайвого. Наприклад, якщо потрібно пропарсити текст до якогось певного символу, він пропарсить його, навіть проковтнувши ключові слова. А якщо потрібно пропарсити арифметичний вираз, потім текст, то він зробить це з легкістю, залишивши непридатний для виразу контент тексту. Припустимо у нас є такий рядок:
Спочатку захопиться текст Here is expression: , потім парсер побачить символ @ і зупиниться, далі він постарається захопити якомога більше символів, придатних під вираз, тобто 50 + a * (b.c - d[0].e()) / 90.0, потім він переключиться до звичайного тексту і захопить . And here goes plain text.... Через те, що парсер працює з текстом безпосередньо, без окремих токенів, він може інтерпретувати текст по-різному, що дозволяє ставити такі ось неочевидні межі для правил, і без використання крапок з комами.
За допомогою такого підходу я з легкістю реалізував парсер для своєї мови шаблонів. До речі, ось демонстрація підсвічування синтаксису:
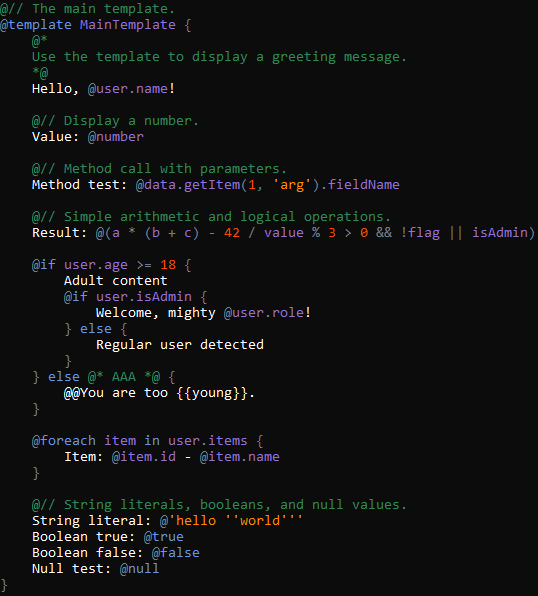 Підсвічування синтаксису, що показує, що все чудово
Підсвічування синтаксису, що показує, що все чудово
Хай мені цього і вистачало для мови шаблонів, все одно хотілося розвинути парсер далі...
Гібридний алгоритм власною персоною
Я якраз розмірковував над створенням ще однієї мови для LLM агентів і пайплайнів (так-так, чергова мова), в якій головну роль гратимуть відступи (як в Python або YAML), плюс мені було просто цікаво створити алгоритм, який може елегантно їх обробляти.
А в чому ж проблема відступів? Справа в тому, що зазвичай парсери не підтримують відступи з коробки (з бібліотек для .NET я знайшов тільки лексерний CSLY), а в разі ANTLR потрібно писати кастомний код для лексера з відстеженням стану (приблизно 80 рядків, гляньте цей код), який буде створювати токени, необхідні для відступів, INDENT і DEDENT. А безлексерні парсери в принципі не здатні парсити таке без диких костилів, так як зміни відступів можуть бути легко пропущені. Наприклад, візьмемо цей шматок коду на Python:
Припустимо, парсер успішно прочитав def func(n):, далі він спробує жадно прочитати якомога більше інструкцій, в підсумку захопивши print(n) і print("Hello!"). Другий print потрапив до списку через те, що парсер жадібний, тобто намагається захопити якомога більше, до того ж, йому ніщо не заважає захоплювати зайві правила. Я задумався, як же вирішити цю проблему без костилів...
І тут до мене в голову прийшла ідея: "А що якщо поставити обмежувачі, які будуть заважати парсеру захоплювати зайві інструкції?". Так і народилася концепція бар'єрних токенів. Суть цієї концепції полягає в тому, що парсер визначає позицію наступного бар'єрного токена, і обмежує видиму область тексту аж до цієї позиції, а якщо ж парсер натикається на бар'єрний токен впритул, то він повинен очікувати даний токен, інакше він просто впаде. Ось як це працює наочно:
 Приклад роботи безлексерного парсера з бар'єрними токенами
Приклад роботи безлексерного парсера з бар'єрними токенами
Спочатку дана така спрощена граматика (для наочності):
Спочатку парсер успішно захоплює оголошення функції, потім намагається пропарсити її тіло. Він успішно парсить токен INDENT, який означає збільшення відступу, потім намагається захопити якомога більше інструкцій, але після захоплення print(n) йому заважає бар'єрний токен DEDENT, тому він повертає лише одну захоплену інструкцію. Потім парсер успішно закриває блок токеном DEDENT і закінчує парсити функцію, потім проходить по решті інструкцій в програмі.
І виходить така схема роботи гібридного парсера:
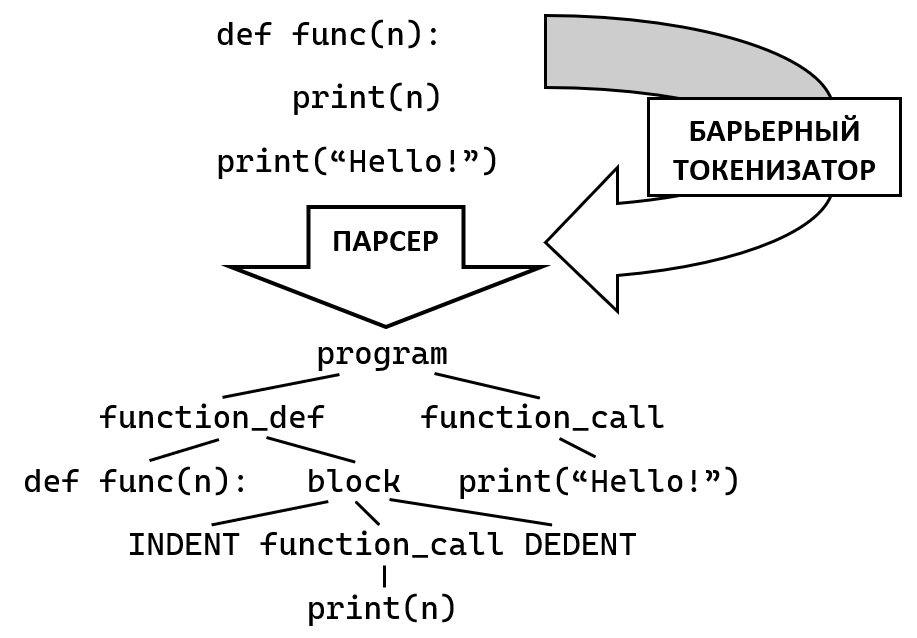 Загальна схема роботи гібридного парсера
Загальна схема роботи гібридного парсера
В гібридному підході токенізується лише значуща частина тексту. Окрім відступів можна, наприклад, токенізувати ключові слова, щоб вони не розпізнавалися як ідентифікатори або щось інше.
Підсумкове порівняння алгоритмів
- Лексерний: Найшвидший алгоритм, але вимагає ретельного налаштування лексера. Не такий гнучкий, як безлексерний. Розрізняють LL(1), LL(*), LR, SLR, LALR та інші. Серед бібліотек для C# використовується в ANTLR, Irony, Superpower, CSLY.
- Безлексерний: Більш потужний і гнучкий підхід, ніж попередній. Дозволяє реалізувати на порядок більше граматик. Продуктивність гірша, але не сильно, все ще в адекватних межах. Розрізняють PEG, Packrat і комбінатори. Серед бібліотек для C# використовується в Sprache, Pidgin, Parakeet, Parlot і в моїй.
- Гібридний: Ще більш потужний підхід, що дозволяє парсити мови, які не можна реалізувати в попередніх. Модифікація безлексерного алгоритму з частковою токенізацією. Швидкість може бути трохи меншою через перевірки на бар'єрні токени.
Реалізація спрощеного YAML з використанням RCParsing
І ось під'їхала практична реалізація парсера з використанням бар'єрних токенів:
Деякі пояснення по коду: ви могли помітити те, що я в коді оголошую токени, але насправді вони просто використовуються як більш швидкі примітиви для парсингу і відрізняються від реальних токенів, які видає звичайний лексер. Токени відрізняються від правил тим, що не можуть мати дочірні елементи, тому ми застосовуємо функцію Pass(index: 1), щоб пробросити при парсингу проміжне значення дочірнього токена вгору. Проміжні значення бувають різні для кожного типу токена (у EscapedTextPrefix це рядок з застосованим екрануванням). Насправді таких "магічних" нюансів в моїй бібліотеці не так вже й багато, якщо навчитися, то можна легко і лаконічно писати власні парсери.
Підсумки
Ну що тут можна сказати? Я був здивований, що існуючі рішення для парсингу в C# не такі гнучкі і зручні (на мою думку), тому зробив за місяць своє. А найголовніше - воно мене дуже навіть влаштовує!
Сподіваюся, і вам сподобається - ось посилання на репозиторій. Там ви зможете знайти більш детальний опис фіч бібліотеки, бенчмарки (на жаль поки без ANTLR, але скоро він там буде), порівняння з аналогами, приклади і документацію. Буду радий побачити ваші коментарі і активність на репозиторії!
Коментарі