
Агенти на базі MCP сьогодні вміють багато: шукати в вебі, працювати з файлами, будувати графіки, рахувати та викликати зовнішні API. Але одна справа — демонстрація на одиничному завданні, інша — стійка робота в реалістичному, змінному середовищі, де відповіді сервісів відрізняються від прогону до прогону, а на вибір доступно відразу кілька десятків інструментів. Більшість наявних бенчмарків цього не відображають: вони короткі, синтетичні, часто без перешкод і майже завжди з фіксованою правильною відповіддю, яка застаріває. Автори LiveMCP-101 спробували закрити цей пробіл.
Що таке LiveMCP-101
LiveMCP-101 — це набір з 101 реальних запитів, який змушує агента координувати кілька MCP-інструментів. Домени — веб-пошук, робота з файлами, математика та аналіз даних. Є три рівні складності: 30 простих, 30 середніх і 41 складних. В середньому завдання вимагає близько п'яти-шести осмислених кроків, іноді — десятки і більше.
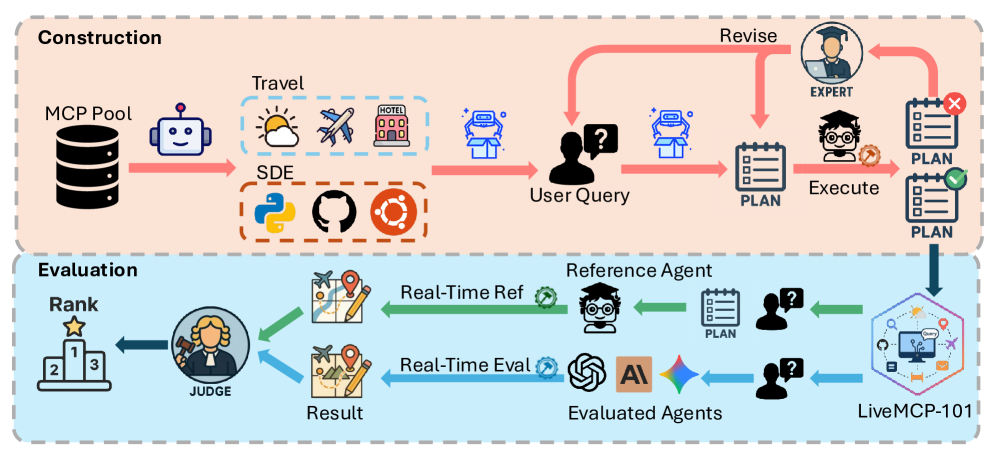
Щоб зробити оцінку стійкою до «живих» відповідей зовнішніх сервісів, автори відмовилися від ідеї фіксувати сирий API-вихід. Замість цього для кожного завдання підготовлений еталонний план виконання. Він уточнювався за траєкторією еталонного агента, поки не починав стабільно приводити до правильного результату. Такий план — не скрипт заради скрипта, а послідовність осмислених дій і параметрів, яку можна зіставити з тим, що робить тестова модель.
Як це оцінюють «вживу»
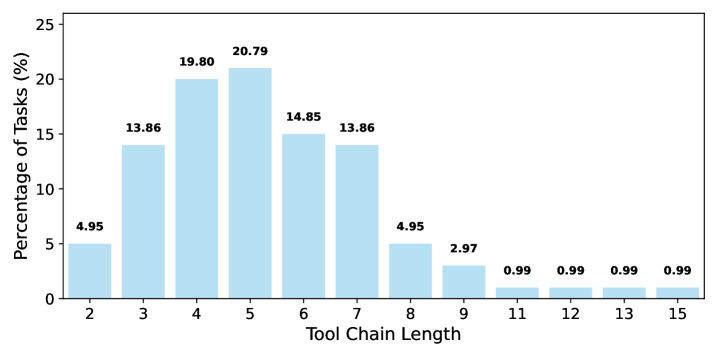
Кожне завдання запускається в двох потоках. Перший — референс: агент строго слідує плану і отримує еталонний вихід. Другий — тест: моделям дають тільки формулювання запиту і великий пул MCP-інструментів (15 серверів і 76–125 інструментів). Оцінка проводиться за кількома метриками: частка повністю розв'язаних завдань (TSR), середній бал результату (ARS), якість траєкторії (ATS), а також середня кількість токенів і число викликів інструментів. Суддя — LLM, чиї оцінки перевіряли на узгодженість з людьми: співпадіння високе, особливо щодо підсумкових відповідей.
Що показали експерименти
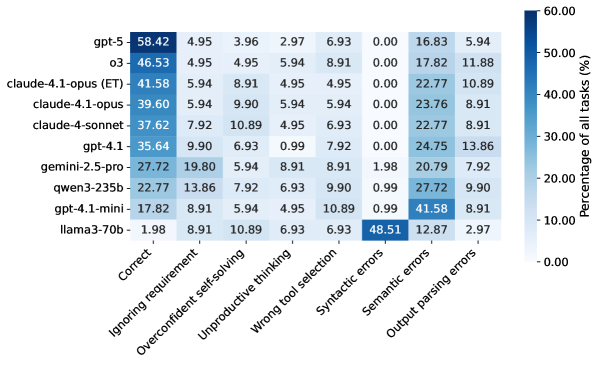
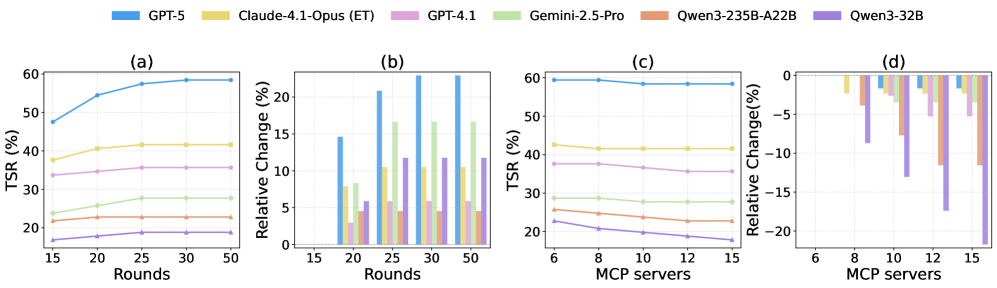
Головне спостереження просте і важливе: навіть найсильніші сьогоднішні LLM справляються менше ніж у 60% випадків. Лідер — GPT-5 з TSR 58.42% в середньому за бенчмарком і 39.02% на складному рівні. Далі — o3 і GPT-5-mini, потім флагманські моделі Anthropic. Середній ешелон помітно відстає, а відкриті моделі — ще сильніше: у найкращих з них показники в районі 20–23% TSR, а у деяких — одиниці відсотків.
Якість траєкторії майже завжди узгоджується з якістю відповіді: чим осмисленіший і чистіший шлях до рішення, тим вищий підсумок. При цьому багатослів'я не рятує: зростання витрачених токенів після певного порогу дає у топ-моделей невелику віддачу. Відкриті моделі часто витрачають більше токенів і більше разів викликають інструменти, але це не перетворюється на надійні відповіді. Посилені міркувальні ланцюжки помітно допомагають — завдяки кращому плануванню і відновленню після помилок.
Де агенти спотикаються
Аналіз відмов виділяє сім типових збоїв, які об'єднуються в три класи:
- Планування та оркестрація: ігнорування вимог або раннє завершення; спроба «розв'язати в голові» без потрібних інструментів; довге непродуктивне міркування; неправильний вибір інструменту.
- Параметри: синтаксичні помилки (не той формат або тип), семантичні помилки (форма правильна, сенс — ні: неправильний ідентифікатор, забуті обмеження).
- Постобробка: інструмент повернув коректну відповідь, але агент її неправильно розпарсив.
Домінують семантичні помилки параметрів — у сильних моделей це 16–25% всіх невдач, у малих — більше 40%. Часто зустрічається і самовпевнене рішення, коли агент ігнорує інструменти і описує відповідь словами.
Що змінюють налаштування
Автори вивчили два важелі. По-перше, ліміт ітерацій: збільшення приблизно до 25 раундів стабільно покращує успіх, далі — згасання ефекту. По-друге, ширина пулу інструментів: чим більше серверів, тим частіше слабкі і середні моделі втрачають точність. Топ-моделі стійкіші, бо краще фільтрують шум і планують економніше.
Чому це важливо
LiveMCP-101 наближає оцінку агентів до реальності: не «ідеальна» офлайн-відповідь, а робота з змінним світом, в великому просторі інструментів, під контролем еталонного плану. Такий формат допомагає фіксувати не тільки «правильність», але і якість шляху, що критично для практичних кейсів. Результати показують, що головний резерв — у плануванні, надійній селекції інструментів, умінні підбирати коректні параметри і акуратно збирати підсумок. Окрема тема — ефективність за токенами: потрібен розумний баланс між мисленням, перевірками і раннім завершенням. Для відкритого стеку напрошуються донавчання на схемах MCP і завданнях з шумом, а також методи суворішої верифікації проміжних кроків.
***
Якщо вам цікава тема ШІ,підписуйтесь на мій Telegram-канал- там я регулярно ділюся інсайтами по впровадженню ШІ в бізнес, запуску ШІ-стартапів і пояснюю, як працюють всі ці ШІ-дива.
Коментарі